Ручное ocr. Обзор программ для распознавания текста. Мнение пользователей о ReadIris
Программы для распознавания текста позволяют конвертировать сфотографированные или отсканированные документы непосредственно в предложения.
Дело в том, что текст на изображении представлен в виде растра, набора точек. Упомянутый софт осуществляет превращение набора точек в полноценный текст, доступный для редактирования и сохранения.
Распознавание букв призвано оптимизировать процесс оцифровки бумажных печатных или рукописных книг, документов.
Такой метод оцифровки на порядки превосходит скорость ручного набора с изображения. Широко применяется при оцифровке библиотек и архивов. Далее рассмотрим пятерку лучших представителей семейства подобных программ.
ABBYY FineReader 10
FineReader безоговорочный лидер среди всех программ, распознающих текст на изображении. В частности, софта, более четко обрабатывающего кириллицу нет. Вообще в активе FineReader 179 языков, текст на которых распознается чрезвычайно успешно.
Единственное обстоятельство, которое может разочаровать пользователей, состоит в том, что программа платная. Бесплатно распространяется только пробная версия на 15 дней. За этот период разрешено сканирование 50-ти страниц.
Дальше за пользование программой придется платить. FineReader легко «кушает» любое более-менее качественное изображение. Источник при этом совершенно неважен. Будь то фотография, скан страницы или любая картинка с буквами.
Достоинства:
- точное распознавание;
- огромное количество языков чтения;
- толерантность к качеству изображения-источника.
Недостаток:
- пробная версия на 15 дней.
OCR CuneiForm
Бесплатная программа для считывания текстовой информации с изображений. Точность распознавания на порядок ниже, чем у предыдущей рассматриваемой программы. Но как для бесплатной утилиты, функционал все-таки на высоте.
Интересно! CuneiForm распознает блоки текста, графические изображения и даже различные таблицы. Более того, считыванию поддаются даже неразлинованные таблицы.
Для обеспечения точности к процессу распознавания подключаются специальные словари, которые пополняют словарный запас из сканируемых документов.
Достоинства:
- бесплатное распространение;
- использование словарей для проверки правильности текста;
- сканирование текста с ксерокопий плохого качества.
Недостатки:
- относительно небольшая точность;
- небольшое количество поддерживаемых языков.
WinScan2PDF
Это даже не полноценная программа, а утилита. Установка не потребуется, а исполнительный файл весит всего в несколько килобайт. Процесс распознавания происходит предельно быстро, правда, полученные в его результате документы сохраняются исключительно в формате PDF.
Фактически весь процесс выполняется при нажатии трех кнопок: выбор источника, места назначения и, собственно, запуска программы.
Утилита предназначена для быстрой пакетной обработки множества файлов. Для удобства пользователей предусмотрен большой языковой пакет интерфейса.
Достоинства:
- портативность;
- быстрая работа;
- простота в использовании.
Недостатки:
- минимальный размер;
- единственный формат файлов на выходе.
SimpleOCR
Отличная небольшая программа для распознавания текстов с изображений. Поддерживает даже чтение рукописей. Беда в том, что русский не входит ни в языковой пакет интерфейса, ни в список поддерживаемых для распознавания языков.
Однако если необходимо отсканировать английский, датский или французский, то лучшего бесплатного варианта не найти.
В своей области программа обеспечивает точную расшифровку шрифтов, удаление шума и извлечение графических изображений. К тому же в интерфейс программы встроен текстовый редактор, практически идентичный WordPad, что значительно повышает удобство использования программы.
Достоинства:
- точное распознавание текста;
- удобный текстовый редактор;
- удаление шума с изображения.
Недостатки:
- полное отсутствие русского языка.
Freemore OCR
Программа позволяет оперативно извлекать текст и графику с изображений. Софт поддерживает работу с несколькими сканерами без потери производительности. Извлеченный текст может быть сохранен в формате текстового документа или документа MS Office.
Кроме того предусмотрена функция многостраничного распознавания.
Распространяется Freemore OCR бесплатно, однако, интерфейс только на английском. Но это обстоятельство никак не влияет на удобство пользования, потому как организованы элементы управления интуитивно понятным образом.
Достоинства:
- бесплатное распространение;
- возможность работы с несколькими сканерами;
- достойна точность распознавания.
Недостатки
- Отсутствие русского языка в интерфейсе;
- Необходимость загрузки русского языкового пакета для распознавания.
Наверное, каждому знакома ситуация, когда скан документа, например, страницы книги, необходимо преобразовать в печатный текст. Для этого существуют специальные программы, но основная их масса очень мало кому известна. На слуху у всех, пожалуй, только ABBYY FineReader. Действительно, FineReader вне конкуренции. Это лучшая программа для сканирования и распознавания текста на русском языке, однако выпускается она исключительно в платных версиях и стоит весьма недешево. Многие ли готовы выложить за самую бюджетную лицензию почти 7 000 рублей, если собираются обрабатывать одну-две книги в год?
Если вы считаете покупку дорогостоящего коммерческого продукта неоправданной, почему бы не воспользоваться аналогами, среди которых есть бесплатные? Да, они не так богаты функциями, но со многими задачами, которые, как считают многие, «по зубам» только FineReader, справляются вполне успешно. Так давайте познакомимся с несколькими доступными альтернативами. И заодно посмотрим, чем они отличаются от общепризнанного эталона.
Чтобы сравнивать другие программы с ABBYY FineReader , выясним, чем же он так хорош. Вот перечень его основных функций:
- Работа с фотографиями, сканами и бумажными документами.
- Редактирование содержимого файлов pdf — текста, отдельных блоков, интерактивных элементов и прочего.
- Конвертация pdf в формат Microsoft Word и обратно. Создание pdf-файлов из любых текстовых документов.
- Сравнение содержимого документов на 35 языках, например, отсканированного бумажного и электронного (не во всех редакциях).
- Распознавание и преобразование сканированных текстов, таблиц, математических формул.
- Автоматическое выполнение рутинных операций (не во всех редакциях).
- Поддержка 192 национальных алфавитов.
- Проверка орфографии распознанного текста на русском, украинском и еще 46 языках.
- Поддержка 10 графических и 10 текстовых форматов входных файлов, не считая pdf.
- Сохранение файлов в графическом и текстовом форматах, а также в виде электронных книг EPUB и FB2.
- Чтение штрих-кодов.
- Интерфейс на 20 языках, включая русский и украинский.
- Поддержка большинства существующих моделей сканеров.

Возможности программы великолепны, но для домашних пользователей, которые не обрабатывают документы в промышленных объемах, избыточны. Впрочем, тем, кому нужно распознать лишь несколько страниц, компания ABBYY предоставляет услуги бесплатно — через веб-сервис FineReaderOnline . После регистрации доступна обработка 10 страниц отсканированного или сфотографированного текста, в дальнейшем — по 5 страниц в месяц. Больше — за доплату.
Стоимость самой недорогой лицензии FineReader для установки на компьютер — 6990 рублей (версия Standard).
Крошечная и крайне простая бесплатная утилитка , конечно, не в состоянии конкурировать с монстром, но основную задачу — распознавание сканированного текста, решает как положено. Причем для этого она не требует даже установки на ПК (портабельная). И управляется всего тремя кнопками.

Для распознавания текста с помощью WinScan2PDF нажмите «Выбрать источник» и укажите подключенный сканер (с готовыми файлами программа, к сожалению, не работает). Поместите в сканер документ и нажмите «Сканировать». Если хотите отменить операцию, нажмите «Отмена». Вот и вся инструкция.
Утилита поддерживает 23 языка, включая русский, и работает с многостраничными файлами. Готовый результат сохраняется в формате pdf, скан документа — в jpg.
Веб-сервис Free-OCR.com
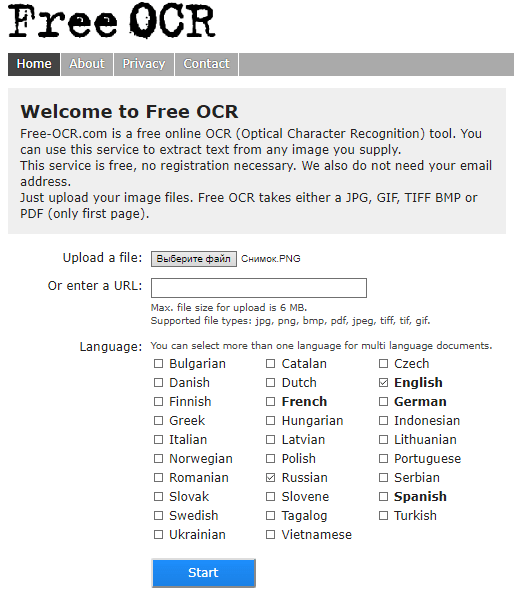
Free-OCR.com (OCR — Optical character recognition, оптическое распознавание символов) — бесплатный Интернет-сервис для распознавания отсканированных или сфотографированных текстов, сохраненных в формате графического изображения (jpg, gif, tiff, bmp) или pdf. Поддерживает 29 языков, включая русский и украинский, причем пользователь может выбрать не один, а несколько, если их содержит исходный текст.
Free-OCR не требует регистрации и не имеет каких-либо ограничений по количеству загруженных документов. Ограничивается только размер файла — до 6 Mb. Многостраничные документы сервис не обрабатывает, точнее, игнорирует всё, кроме первого листа.
Скорость распознавания сканированного текста довольно высока. Лист А4 с фрагментом книги на русском языке был обработан примерно за 5 секунд, но вот качество не порадовало. Крупные шрифты — как в детских книжках, он распознает на 100%, а средние и мелкие — примерно на 80%. С англоязычными документами дела обстоят несколько лучше — мелкий и неконтрастный шрифт распознался правильно примерно на 95%.
Веб-сервис Free Online OCR
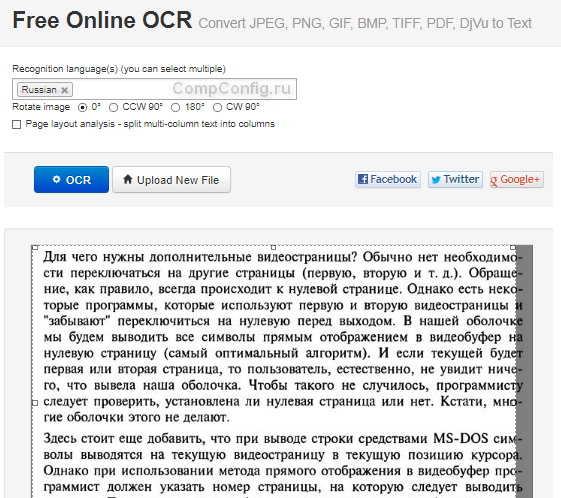
— еще один бесплатный веб-сервис, очень похожий на предыдущий, но с расширенным функционалом. Он:
- Поддерживает 106 языков.
- Обрабатывает многостраничные документы, в том числе на нескольких языках.
- Распознает тексты на сканах и фотодокументах множества типов. Помимо 10 форматов графических изображений, обрабатывает документы pdf, djvu, doxc, odt, архивы zip и сжатые файлы Unix.
- Сохраняет выходные файлы в одном из 3 форматов: txt, doc и pdf.
- Поддерживает распознавание математических уравнений.
- Позволяет повернуть изображение на 90-180° в обе стороны.
- Правильно распознает текст в нескольких столбцах на одной странице.
- Может распознать один выбранный фрагмент.
- После обработки предлагает скопировать файл в буфер обмена, скачать на компьютер, загрузить на сервис Google Docs или опубликовать в Интернете. Также доступна возможность сразу перевести текст на другой язык, используя Google Translate или Bing Translator.
Надо отдать должное Free Online OCR и за то, что он неплохо читает картинки низкого разрешения и малой контрастности. Результат распознавания всех скормленных ему русскоязычных текстов отказался стопроцентным или близким к этому.
Free Online OCR, по нашему мнению, одна из лучших альтернатив FineReader, но бесплатно он обрабатывает только 20 страниц (правда, не указано, за какой период). Дальнейшее использование сервиса стоит от $0,5 за страницу.
Microsoft OneNote
Программа для создания заметок Microsoft OneNote , исключая очень старые и последнюю — 17 версии, тоже содержит функционал OCR. Он не такой продвинутый как в специализированных приложениях, но тоже пригодный к использованию, если нет других вариантов.
Чтобы распознать текст с изображения с помощью OneNote, вставьте картинку в файл («Рисунок» — «Вставить»), нажмите на нее правой клавишей мышки и выберите «Копировать текст из рисунка».

После этого вставьте скопированный текст в любое место заметки.
По умолчанию языком распознавания назначен английский. Если вам нужен русский или какой-либо другой, измените настройку вручную.
Качество распознавания русскоязычного текста в Microsoft OneNote оставляет желать лучшего, поэтому его нельзя назвать полноценной заменой FineReader. Да и обрабатывать в нем большие многостраничные документы весьма неудобно.
SimpleOCR

Старенькая бесплатная программа SimpleOCR — тоже весьма достойный инструмент распознавания текстов с электронных изображений и сканов, но, к сожалению, без поддержки русского языка. Зато в ней есть уникальная функция считывания рукописных слов, а также редактор, позволяющий исправить ошибки перед сохранением готового результата.
Другие возможности SimpleOCR:
- Проверка орфографии с возможностью пополнять словарь вручную.
- Чтение документов в низком разрешении и с помарками (есть опция очистки «шума»).
- Максимально близкая подборка шрифта и передача стилей написания (жирный, курсив). При желании функцию можно отключить.
- Одновременная обработка нескольких листов или отдельного фрагмента.
- Выделение возможных ошибок в готовом тексте для ручного редактирования.
- Поддержка множества модификаций сканеров.
- Входные форматы электронных документов: tif, jpg, bmp, ink, а также сканы.
- Сохранение готового текста в форматах txt и doc.
Качество распознавания и печатных текстов, и рукописей довольно высокое.
Программу можно было бы назвать универсальной, если бы не ограничение языковой поддержки. Последняя версия поддерживает только английский, французский и датский языки, добавление других, скорее всего, не планируется. Интерфейс полностью на английском, но прост для понимания. Кроме того, в главном окне есть кнопка «Demo», которая запускает обучающий ролик по работе с SimpleOCR.

Программа бельгийской компании-разработчика I.R.I.S — вот это действительно настоящий конкурент российскому ABBYY FineReader. Мощная, быстрая, кроссплатформенная, основанная на фирменном OCR-движке, используемом производителями Adobe, HP и Canon, она великолепно распознает даже самые трудночитаемые тексты. Поддерживает 137 языков, среди которых есть русский и украинский.
Особенности и функции Readiris:
- Самая высокая скорость обработки файлов среди приложений такого класса, рассчитано на большие объемы.
- Сохранение форматирования исходного текста (шрифты, кегль, стиль написания).
- Одиночная и пакетная обработка файлов, поддержка многостраничных документов.
- Распознавание математических уравнений, специальных символов и штрих-кодов.
- Очистка текста от «шумов» — линий, помарок и т. п.
- Интеграция с различными облачными сервисами — Google Документы, Evernote, Dropbox, SharePoint и некоторыми другими.
- Поддержка всех современных моделей сканеров.
- Форматы входных данных: pdf, djvu, jpg, png и другие, в которых сохраняют графические изображения, а также полученное непосредственно со сканера.
- Форматы выходных данных: doc, docx, xls, xlsx, txt, rtf, html, csv, pdf. Поддерживается конвертация в djvu.
Интерфейс программы русскоязычный, использование интуитивно понятно. Она не предоставляет пользователям возможности редактировать содержимое файлов pdf, как FineReader, но с главной задачей — распознаванием текстов, на наш взгляд, справляется отлично.
Readiris выпускается в двух платных версиях. Стоимость лицензии Pro составляет 99,00€, Corporate — 199€. Почти как у ABBYY.
Freemore OCR

Freemore OCR — (! сайт программы http://freemoresoft.com/freeocr/index.php может блокироваться антивирусами из-за встроенного в установщик рекламного «мусора») — еще одна простая, компактная и бесплатная утилитка, которая тоже неплохо распознает тексты, но по умолчанию только на английском. Пакеты других языков нужно загружать и устанавливать отдельно.
Прочие функции и возможности Freemore OCR:
- Одновременная работа с несколькими сканерами.
- Поддержка множества форматов графических данных, в том числе проприетарных, вроде psd (файл Adobe Photoshop). Стандартные форматы графики поддерживаются все.
- Поддержка pdf.
- Сохранение готового результата в формате pdf, txt или docx, причем для экспорта текста в Word достаточно нажать одну кнопку на панели инструментов.
- Встроенный редактор (к сожалению, форматирование исходного документа программа не сохраняет).
- Просмотр свойств документа.
- Печать распознанного текста прямо из главного окна.
- Защита паролем файлов в формате pdf.
На первый взгляд интерфейс программы может показаться сложным, но на самом деле пользоваться ею очень легко. Инструменты поделены на группы, как на ленте Microsoft Office. Если рассмотреть их повнимательнее, назначение той или иной кнопки быстро станет понятным.
Чтобы загрузить электронный документ в окно Freemore OCR, сначала выберем его тип — изображение или файл pdf, и следом нажмем соответствующую кнопку «Load». Чтобы начать процесс распознавания, нажимаем на кнопку «OCR» в одноименной группе инструментов рядом с изображением волшебной палочки (показана на скриншоте).
Результат сканирования англоязычных текстов как с хорошо-, так и с плохочитаемой картинки оказался вполне удовлетворительным. Не понравилось лишь одно — то, что вместе с программой на компьютер устанавливается всякий мусор — какие-то липовые антивирусные сканеры, оптимизаторы и прочие ненужные вещи, причем без возможности отказаться от них во время установки. Словом, если бы не этот недостаток, приложение можно было бы рекомендовать в качестве неплохой бесплатной альтернативы FineReader.
Оптическое распознавание текста – процесс, при котором сфотографированный или отсканированный текст, с помощью специальной программы, переводится в формат документа.
То есть, вместо картинки вы будете иметь стандартный набранный текст, который можно редактировать.
В данном материале мы обсудим, какая программа для распознавания текста лучше (ТОП-7 утилит приведены ниже).
Выбор
Как же выбрать наиболее подходящую программу, и какие основные особенности имеет такой софт?
Отличаться он может по разным показателям – точности распознавания, способности работать с тем или иным языком, возможности сохранять исходную структуру текста и т. п.
Такой софт может распространяться платно и бесплатно, и быть реализован как онлайн (в виде особых сервисов), так и в форме предустанавливаемых программ.
Алгоритм работы заключается в том, что для каждой буквы алфавита составляется база вариантов того, как она может выглядеть на фото, выделяются и сохраняются ее основные элементы. Как только такие элементы обнаруживаются на фото, программа распознает соответствующую букву. В зависимости от того, насколько качественно и подробно была составлена такая база, зависит качество распознавания материала в итоге.
Потому важно, чтобы софт был рассчитан на работу именно с русским языком (некоторые программы могут работать с текстом, написанным сразу на двух языках, другие – нет).
Кроме того, некоторые утилиты и сервисы способны сохранять даже изначальную структуру текста ( , списки), тип его оформления (отступы и т. п.) и даже .
В каких же случаях такой софт необходим?
- При создании документов, когда имеется только распечатанный вариант;
- При составлении рефератов, докладов и необходимости процитировать в них большой отрывок текста из книги;
- Для редакторских работ, когда текст имеется лишь в формате фото и т. д.
На самом деле сфера использования софта очень велика, и правильно выбранный, он способен облегчить и ускорить работу с текстом.
Технические характеристики
Софт отличается по многим параметрам: способу реализации (онлайн или в виде утилиты), лицензии на использование (платно или бесплатно), списку распознаваемых языков, качеству распознавания и другое.
Для того, чтобы пользователь мог сделать правильный выбор максимально быстро, ниже в таблице приведены основные характеристики таких программ.
| Названия | Лицензия | Сканирование | Проверка орфографии | Перевод | Обработка текста в редакторе | Работа с рукописным текстом | Работа с изображениями плохого качества |
|---|---|---|---|---|---|---|---|
| Abbyy Fine Reader | Платно, с бесплатным пробным периодом на 10 дней | да | да | да | частично | частично | да |
| OCR Cunei Form | Бесплатно | да | да | нет | да | нет | да |
| Readiris Pro | нет | да | нет | да | да | да | |
| OCR Freemore | Бесплатно | да | нет | нет | да | нет | да |
| Abbyy Screenshot Reader | Платно, с бесплатным пробным периодом на 14 дней | нет | да | да | нет | нет | частично |
| Adobe Acrobat | Платно, с бесплатным пробным периодом на 7 дней | да | нет | нет | частично | нет | частично |
| Free Online OCR | Бесплатно | нет | нет | нет | нет | частично | да |
Все утилиты, перечисленные в таблице, ниже описаны подробно, и размещены в порядке ТОПа, от лучшей к худшей.

Abbyy Fine Reader

Это наиболее качественный и многофункциональный софт в данном ТОПе. Он отличается высокой точностью распознавания и имеет целый ряд преимуществ, распространяется платно.
Программа успешно работает со множеством языков, в ходе распознавания способна сохранять структуру текста и тип его форматирования.
Предназначена для профессионалов, потому, по мнению большинства пользователей, своих денет стоит.
- Большое количество поддерживаемых языков;
- Способность сохранять стиль форматирования и особенности структуры документа достаточно точно;
- Наличие бесплатной пробной версии на 10 дней;
- Отсутствие снижения качества работы даже при больших объемах текста (что нередко наблюдается у других программ, которые хуже и хуже распознают текст с каждой последующей загруженной фотографии, и проблема устраняется только после перезапуска).
Отзывы о данном софте различны: «Хорошая программа, очень помогает в работе», «Не стоит своих денег – есть и бесплатные программы с таким же качеством распознавания».
OCR Cunei Form

OCR Cunei Form – пожалуй, одна из наиболее функциональных и удобных программ, среди тех, что распространяются бесплатно.
Обеспечивает достаточно высокое качество распознавания, работает даже с фотографиями плохого качества.
Программа позволяет редактировать фото прямо в процессе работы с ним, достаточно хорошо распознает шрифты и структуры (хотя и не работает с рукописным текстом).
Способна напрямую, и отправлять их в редактор в текстовом виде.
Имеет достаточно удовлетворительную скорость работы.
- Высокое качество распознавания;
- Поддержка большого количества языков;
- Бесплатное распространение;
- Довольно высокая скорость работы.
- Отсутствие встроенного переводчика;
- Никое качество проверки на орфографию;
- Отсутствие возможности работы с рукописным текстом.
Отзывы юзеров об этой программе таковы: «Неплохой софт», «Учитывая, что программа бесплатная, работает просто отлично».
Readiris Pro

Readiris Pro – еще один платный софт, обеспечивающий достаточно разнообразную и стабильную работу по распознаванию и редактированию теста.
У пользователей, которым приходится работать с документами, иногда возникает необходимость перевести текст с бумаги в цифровой документ, чтобы с ним можно было впоследствии работать в текстовом редакторе. Набирать текст с листка вручную - занятие довольно трудоемкое и неблагодарное, особенно если этого текста не один листик, а страниц 20-30, или даже больше. В таком случае может сильно пригодиться специальный инструмент для распознавания текста, называемый OCR (Optical Character Recognition). Программа оптического распознавания текста поможет выиграть время, которое вы могли бы потратить на перепечатку текста, а также даст возможность сохранить иллюстрации, что порой тоже очень важно. В данной статье мы проведем небольшой обзор наиболее популярных и востребованных OCR-инструментов
ABBYY Fine Reader
Программа ABBYY Fine Reader является одним из лучших инструментов для распознавания отсканированных документов. Также данная программа может распознавать PDF и DjVu-файлы.

Fine Reader имеет встроенный текстовый редактор с проверкой орфографии, может проводить распознавание текста с изображений почти всех форматов, поддерживает более 180-ти языков. Программа позволяет проводить довольно качественное извлечение текста даже из тех изображений, которые были сделаны при помощи цифровой камеры и имеют неравномерное освещение и недостаточную резкость.
Программа ABBYY Fine Reader выпускается в трех версиях: Home Edition, Professional Edition и Corporate Edition. Первая версия предназначена для домашнего использования и имеет слегка упрощенный интерфейс, вторая больше подходит для профессиональной работы с текстом, так как ее функциональность несколько шире, а версия Corporate Edition ориентирована на совместное использование в различных организациях.
ABBYY Fine Reader является платной программой, пробную демо-версию продукта можно бесплатно скачать на официальном сайте разработчика, который находится по адресу Abbyy.ru
OmniPage
OmniPage – это еще один качественный профессиональный инструмент для распознавания текста с графических и PDF-файлов. Программа обеспечивает качественное и быстрое распознавание документа с полным сохранением его структуры, что особенно важно при распознавании документов, которые содержат таблицы.

OmniPage имеет поддержку более чем 120 языков, также в программу встроены распознавательные словари для юридических, финансовых и медицинских терминов. Помимо распознавания текста, программа также имеет такие функции, как конвертация документов в PDF, конвертация электронных документов в аудиофайл и распознавание текста с изображения напрямую в аудиофайл.
Программа OmniPage также платная, приобрести ее можно на официальном сайте разработчика - Nuance.com .
OCR CuneiFrom
Программа OCR CuneiFrom после разработки позиционировалась как платный продукт, однако со временем компания-разработчик стала распространять ее бесплатно и даже открыла исходные коды программы, предложив всем желающим принять участие в улучшении работы программы. OCR CuneiFrom имеет простой, но приятный интерфейс, и может распознавать текст на более чем 20-ти языках. При распознавании программа сохраняет форматирование текста и расположение таблиц, а встроенные алгоритмы оптического распознавания позволяют выполнять извлечение текста даже из нечетких ксерокопий и факсов.

Программа OCR CuneiFrom является, пожалуй, лучшим бесплатным инструментом для распознавания документов. Скачать бесплатно данную утилиту можно на официальном сайте разработчика по адресу Cognitiveforms.ru .
Помимо программ для распознавания текста, вы можете воспользоваться еще и специальными сервисами, с помощью которых можно выполнять распознавание документов в режиме онлайн. Разумеется, их возможности несколько ограничены по-сравнению с возможностями специализированных программ, однако для небольших объемов такие сайты вполне сгодятся.
Foxit’s Maestro Server OCR converts paper and scanned documents into searchable PDF files. Engineered for automated, high-volume document scanning & OCR needs, Maestro replaces manual document processes with fast, cost-efficient operations.
Maestro automates the OCR process by converting any document as it enters a watched folder according to configurable settings chosen by the user. Beyond OCR automation, Maestro incorporates unlimited multi-threading and batch OCR to accommodate high-volume scanning, up to billions of pages per year to make Maestro a robust enterprise OCR software solution.
Maestro is designed for high OCR accuracy, speed, and simplicity. The software delivers highly accurate text recognition rates by utilizing in-house PDF expertise as well as a proprietary voting OCR engine. Further, Maestro can process up to 6,000 pages per hour per core (on average) to handle the highest volume environments while accelerating business processes and improving labor productivity. It is a flexible OCR solution which integrates easily into existing document imaging workflows while providing multiple workflow accessibility, allowing users to perform many image processing functions beyond OCR.
Server OCR Use Cases
Convert Scanned Documents to Searchable PDF
Generate searchable PDF assets from paper and image documents from a scanner, fax, or MFP that can be utilized more effectively in your systems and workflows.
Enable Insights and Automation
Maestro provides high OCR accuracy to reduce errors and automatically create great data to feed into your RPA, document indexing, and big data analytics systems.
Improve Employee Productivity with Faster Information Search
Replace costly, manual information hunting with simple, instant keyword search using Optical Character Recognition software.
Enable Compliance with Regulatory Submission Requirements
Regulated environments often require full text-searchable PDF submission, such as when applying for NDAs to the FDA in the life sciences space.
Create More Accessible Documents
Screen readers and other assistive technologies require text layer data to function properly. Create more accessible documents with automated OCR.
Optimize Document Archiving and Mitigate Legal Exposure
Comply with records retention requirements by converting TIFFs, JPGs, BMPs, and paper to digital, ISO-certified PDF/A documents.
Maestro Server OCR Software Features
OCR Software for Highly Efficient Document Scanning, Storage and Retrieval
Enterprises, government agencies, and growing organizations utilize Maestro Server OCR to reliably and efficiently convert their scanned paper and image documents to text searchable PDF files. Maestro combines image pre-processing and a proprietary voting OCR engine to deliver high text recognition accuracy out of the box, substantially reducing errors compared to manual document processing from human error.
In addition, the OCR software utilizes automation and multiple high-volume processing capabilities to streamline document scanning, storage, and archiving workflows even at an enterprise scale. Faster OCR pushes documents through business processes faster, facilitating shorter response times to customers, better CSAT, and places your organization in a better position to generate new revenue as a result.
OCR Accuracy, Reliability in Maestro Server OCR
Highly accurate OCR can replace hours spent manually searching for critical information with a simple, instant keyword search. The OCR engine within Maestro is one of the most accurate OCR products available. Maestro"s OCR recognizes difficult text often missed by competing products, including text within low resolution captured documents, documents containing multi-directional text, and documents containing low-contrast color text.
More accurate OCR results translate into greater efficiency in indexing, searching for, and working with scanned documents. It also enables more accurate data extraction, data mining for big data applications, and more efficient employees. With Maestro, users are able to instantly locate a single word within a multi-page document that may contain 1 or 1,000 pages; this is analogous to finding the needle in a haystack.
Image Processing
Maestro Server OCR also offers advanced image processing capabilities. With Maestro, images can be de-skewed & de-speckled for enhanced document quality. Maestro also supports IP features including auto-rotation, auto color inversion, auto-cropping, and color re-sampling. Maestro"s robust image processing functionality provides enhanced image quality prior to processing with highly accurate OCR.
Advanced PDF Control
Maestro Server OCR provides superior PDF control including: PDF linearization, advanced security, PDF/A compliance, metadata insertion, PDF display control, Bates stamping, and headers & footers. Maestro can output a linearized PDF for fast web view, allowing users to view a specified page within the PDF immediately while the rest of the document loads in the background. Maestro also provides advanced security functionality, including options for edit-protection, print-protection, and read-protection. With Maestro, users can reliably archive their documents with PDF/A compliance.
OCR Software Feature Summary
Intel Pentium Processor or compatible 2.0 GHz and higher
Cores
At least 2 cores is recommended
RAM
1GB RAM per core (At least 2GB per core is recommended)
OS
Windows 10 / 8.1 / 8 / 7 / 2012 / 2008
Linux Users
Run Windows emulation using VirtualBox 3 or later (VirtualBox is freeware)
Mac Users
The following are two methods in which you can run Foxit software on a Mac:
- Mac OS X running on an emulation (VM Fusion 2.0) of Windows
- Mac running on a Windows Operating System (directly or using Bootcamp)